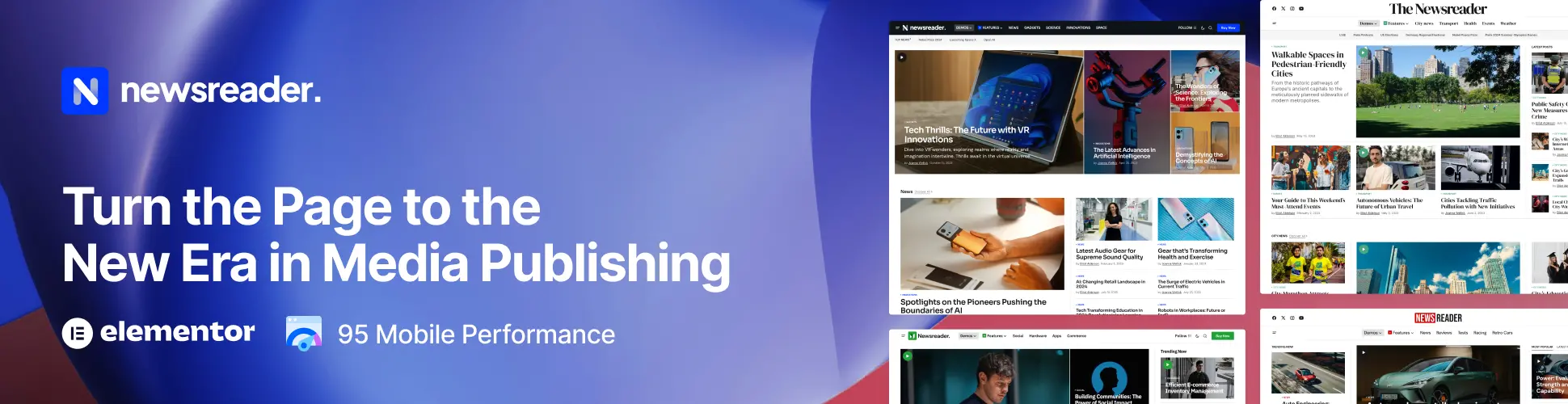
Motivating Content What are Effects of Goal Orientation on Student Achievement? byNageshwar DasApril 30, 2026